Branching out: No REST for the wicked - Part 1
Wed 22 Jan 2020, 12:08 PM
by Ben Langhinrichs
Posts in this series:
While Node JS stuff is the newest, I'm going to start back at the REST API logic available in Domino Access Services. (If you thought I was going to post about the song by Cage the Elephant, you might have missed the gist of this blog, though I do like the song.) I'm pretty sure DAS was added in Domino 8.5.3, though the documentation is a bit scattered. The most reliable resource seems to be written by Dave Delay at https://github.com/OpenNTF/das-api-specs. While this is useful, it is hard not to notice that the last update was two years ago.
So, is DAS still relevant? I think so, though I'd love to hear from others. I do know that the AppDev Pack 1.0.3, which is very recent, has support for the OAuth DSAPI Extension as part of IAM, which supports the OAuth2 Introspection Protocol. In other words, you can use the same IAM services to authenticate a DSAPI like DAS as you can with the NodeJS stuff. Note that I say a "DSAPI like DAS" because you can write your own DSAPI to handle REST calls. That's exactly one of the things I am doing for a beta we are releasing in the not too distant future, though we are not doing this instead of Node JS, but rather in addition to it.
Domino Access Services for Tree Huggers (Documents and Views Edition)
Okay, so this is where I try to explain (figuring out as I go) what you can and can't do, and how you do hat you can. While their is support for calendar events, busytime, mail, and directory stuff, I'm going to leave that for some other enterprising person to document, I'm going to focus on documents I'll try not to get too geeky, as I'll have to refer back to this post and want to remember what the hell I was talking about. I'll focus on your basic CRUD (Create/Read/Update/Delete), though for the sake of what people usually do, I'll switch that to the less memorable ARCUD (Access/Read/Create/Update/Delete) since that is the order we tend to need stuff. Acess is how we get to the documents in the first place.
0) Access - Getting a list of collections (views and folders) from a database
If you were paying attention in my previous post, and I hardly blame you if you didn't, you need to set up a database to allow DAS access first. Assuming you have done that, you now have a few URL endpoints you need to know about. I could just say URLs, but would you be as impressed? I thought not. In any case, you could start with
to get the array of views and folders. You can just type this in a browser, but technically that is doing a GET using HTTP. I downloaded Postman (because Jesse Gallagher suggested it), a free utility which supports all kinds of protocols and is easy to use. So, if I do this in Postman (specifying the port because of reasons), I get the result below. Particularly notice the red arrows. First shows the URL endpoint and that this is a GET. The second shows the Response code of 200, which means the HTTP request was accepted and responded to. The third arrowshows in the JSON the URL endpoint for a specific view.
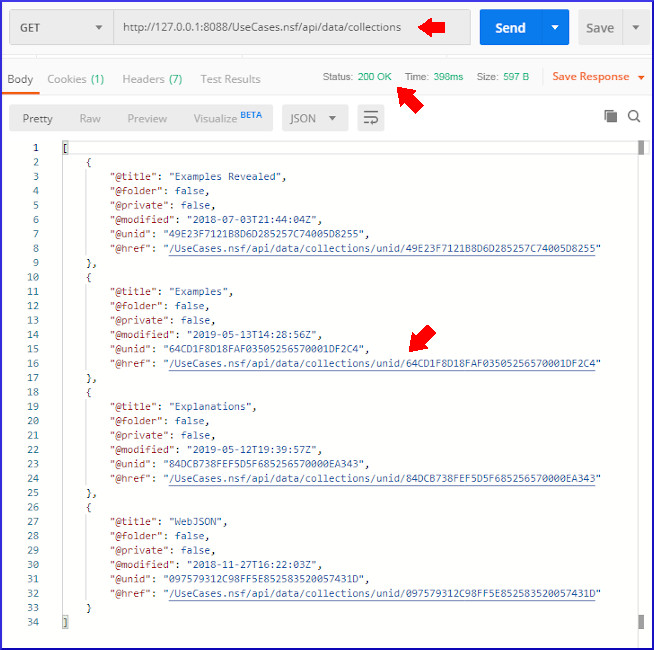
We will do a second GET with the new URL endpoint for that collection, which we can see is called "Examples", and since it is not private and not a folder, is a public view. There, we will see all the view entries retrieved., I'll focus in on the one view entry for the document I want to read. The red arrow points to the URL for the specific document. Note that instead of being accessed through /api/data/collections, it is accessed through /api/data/documents.
So now, we have the URL for the specific document, and can move from Access to Read.
1) Read - Getting the contents of a Notes document and all its fields in JSON
When we read a document using DAS, we get a combination of system information about the document as well as the specific fields. In the image below, I numbered the arrows to make it clear what you are seeing. 1) The url used to access this document; 2) the system fields: form, unid, noteid, creation & modification dates, authors; 3) the rich text field Body which has been rendered as multipart MIME; 4) the plaintext rendering inside that MIME; and 5) the HTML rendering inside that MIME.
The decision to use MIME is not surprising, as the Notes/Domino code already supports converting from rich text to MIME, and the MIME parts can include all of the images and attachment references. See the image below for the images and attachments represented as separate MIME parts with all the images and attachments base64 encoded so they can be included in the JSON.
But while MIME was easy for IBM to add, it isn't ideal for a variety of reasons. The rendering isn't so great, as we'll see, and there isn't a lot of support for turning a MIME representation in JSON or JavaScript into a web page. It can be done, but it is not straightforward. There is also a real question about whether these should be included inline, especially the attachments, or referenced in a way that can be accessed. When you get a web page generated by Domino, the attachment is referenced as /db.nsf/view/unid/$File/attachment.xls so that it doesn't have to get passed back and forth unless it is needed. I could not find any way to enable that with DAS, though there might be.
In any case, so far this has been fairly straightforward URL access to documents, and even those tree huggers amongst us who don't know what REST APIs are can use URLs. Let's get to the stuff that may be less obvious.
2) Create - Making a new document with a JSON representation
The URL for creating a new document is fairly simple. You just use the part without the unid/AE05828B3D7CCB9585257E9F006D13BD
But if you use that URL in a browser, you will get a generic collection of all documents in the database, which is handy but not for this purpose. The reason is that the URL in a browser is always doing a GET, and to create something, we need to do a POST. This is where Postman (see where the name came from?) is useful. Let's take the actual response we got from reading the document above, and turn it around to create a new document, All we really have to do is switch from GET to POST with the exact same URL, but we call also change the JSON. (You have to copy thee JSON and switch to POST and then click on 'raw' and paste it back in before modifying.) In this case, I'm going to change the subject from Better Budgies to Better Budgies 2. My tendency is to also remove the system fields for @unid and @noteid, but it isn't necessary. They are ignored when creating a new document with POST. So, let's give it a try.
First, here's the part of the Examples view with the Better Budgies document.
Second, we'll copy, paste, modify the JSON and switch to POST as the method.
Oops, do you see what I did wrong? I got the response back below.
I forgot to get rid of the /unid/AE05828B3D7CCB9585257E9F006D13BD in the URL. When I remove those and try again, I get another error.
That's right, when I do a POST, I have to specify what type of content I am posting, as it could be HTML or a file attachment or whatever. So, I need to add a Header, which is easy in Postman, that sets the Content-Type to application/json. I try, and this is what I get.
The status code of 201 is a bit different than the 200 I got before. Both mean success, but this means the content was posted and created. Let's take a look at the view now.
Notice that underneath the Better Budgies post, there is now a Better Budgies 2 post. You might also notice that the size is quite different. While the document should have all the same fields, you'll find that the rich text field in Better Budgies been saved as a MIME field in Better Budgies 2. That conversion leads to some loss, which is one downside of using Domino Access Services with any application with rich text. Spoiler alert: that roundtrip fidelity is one of the things we specialize in at Genii Software, so the product we create will handle this better. In any case, here's the difference:
Well, this blog post is long enough already, so I'll continue with the topic in a separate post that will cover Update and Delete.
Copyright © 2020 Genii Software Ltd.
